Order Brushing Problem (Shopee Code League 2020)
Shopee Code League là một thử thách lập trình trực tuyến kéo dài 02 tháng bao gồm một loạt các cuộc thi, câu hỏi về thuật toán trực tuyến và hội thảo đào tạo trực tuyến dành cho tất cả sinh viên và các chuyên gia trên toàn khu vực (xem thêm tại Shopee Code League 2020). Challenge đầu tiên vừa diễn ra là Order Brushing Problem (Chủ đề Data Analytics). Mình cùng teammate vừa hoàn thành xong challenge này, dù chưa xây dựng được giải pháp tối ưu nhất (score: 0,98/1,0) nhưng cũng giới thiệu đến các bạn giải pháp của nhóm trong bài toán này.
Mục lục
1. Quan sát dữ liệu
Team mình tham gia hạng mục Open nên mình chỉ bàn về đề bài ở hạng mục này.
Có thể xem đề bài và mô tả dữ liệu trên Kaggle: [Open] Shopee Code League - Order Brushing
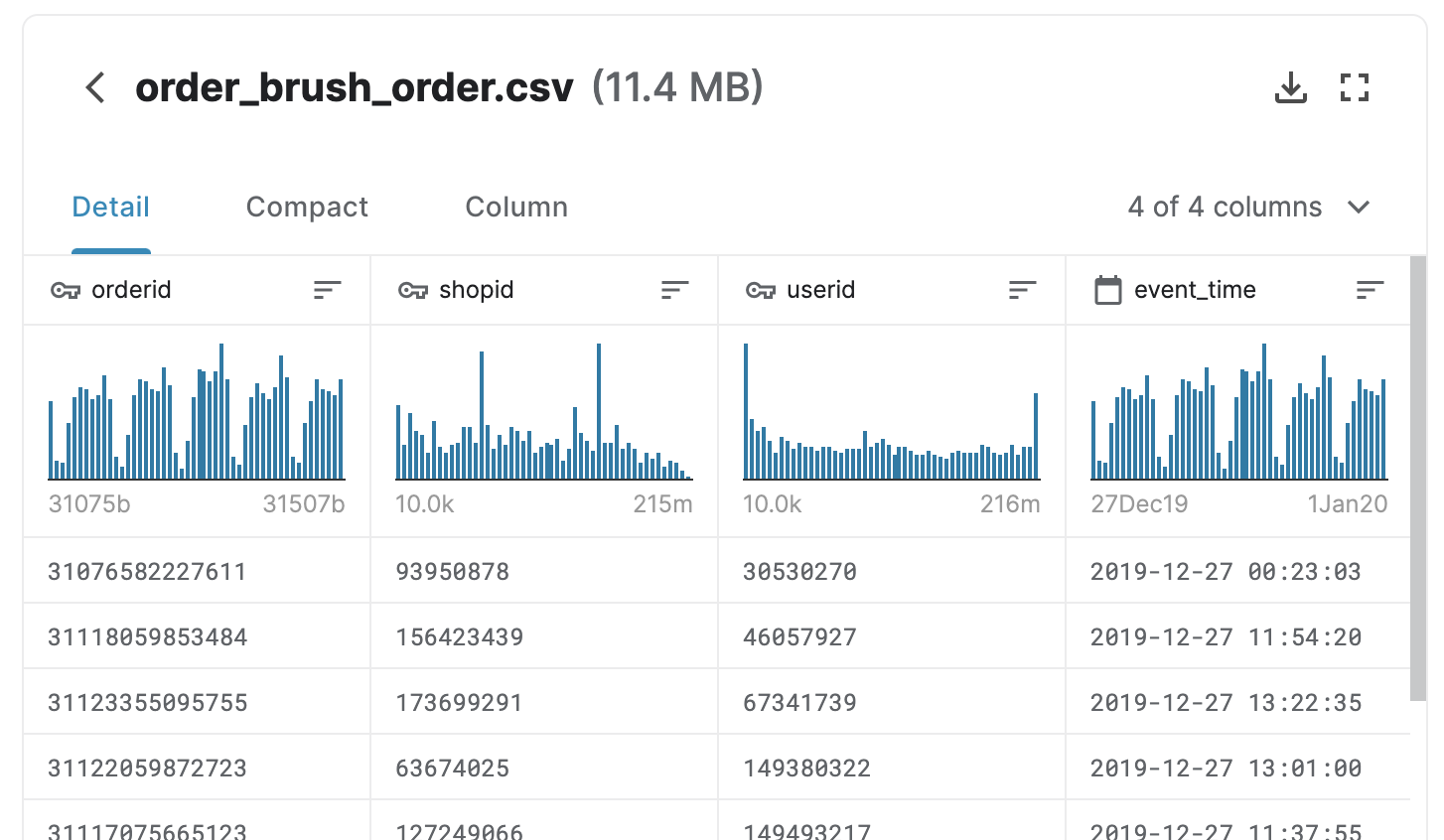 Dữ liệu được public trên Kaggle
Dữ liệu được public trên Kaggle
Dữ liệu có 222.750 dòng x 4 cột:
- orderid: Mã đơn hàng, duy nhất trên toàn bộ dữ liệu.
- shopid: Mã shop, là một người bán hàng trên nền tảng Shopee.
- userid: Mã user, là một người mua hàng của shop đó trên nền tảng Shopee.
- event_time: Thời điểm user đặt hàng của shop.
Như vậy, một dòng dữ liệu thể hiện cho một lần user đặt hàng của một shop trên nền tảng Shopee.
2. Phân tích yêu cầu
Ý nghĩa của Order Brushing: là một kỹ thuật “đánh bóng” đơn hàng. Trong kỹ thuật này, người bán hàng có thể tạo ra các đơn đặt hàng giả nhằm tăng lượt tương tác, hoặc danh tiếng của người bán hoặc một mặt hàng cụ thể trong bảng xếp hạng. Mục tiêu là thăng hạng của người bán hoặc món hàng đó lên các kết quả tìm kiếm trên Shopee.
Mục tiêu của đề bài:
- Nhận diện tất cả các shop có dấu hiệu sử dụng kỹ thuật order brushing.
- Trong các shop này, nhận diện các user có dấu hiệu thực order brushing cho shop đó.
Đề bài mô tả các rule để tìm ra các đơn hàng brushing như sau:
- Một shop được xác định là tiến hành order brushing nếu có concentrate rate lớn hơn hoặc bằng 3:
$$Concentrate\ rate = \frac{Number\ of\ Orders\ within\ 1\ hour\ of\ shopid}{Number\ of\ Unique\ Buyers\ within\ 1\ hour\ of\ a\ shop}$$
- Sau khi đã xác định được shop, cần xác định các user thực hiện order brushing cho shop đó. Với mỗi unique user đặt hàng shop đó, user nào có tỉ lệ user proportion cao nhất sẽ là user cần tìm. Trường hợp có nhiều user cùng tỉ lệ cao nhất thì tất cả các user đó cũng sẽ là user cần tìm.
$$User\ proportion\ in\ brushing\ time = \frac{No.\ Orders\ of\ User}{No.\ Orders\ of\ Shop}$$
Để hiểu hơn các trường hợp cụ thể, các bạn có thể xem diễn giải tại đây.
3. Tìm giải pháp
Load dữ liệu và xem những thuộc tính của dữ liệu:
d1 = pd.read_csv(os.path.join(dirname, filename), header=0, parse_dates=[3])
d1.dtypes
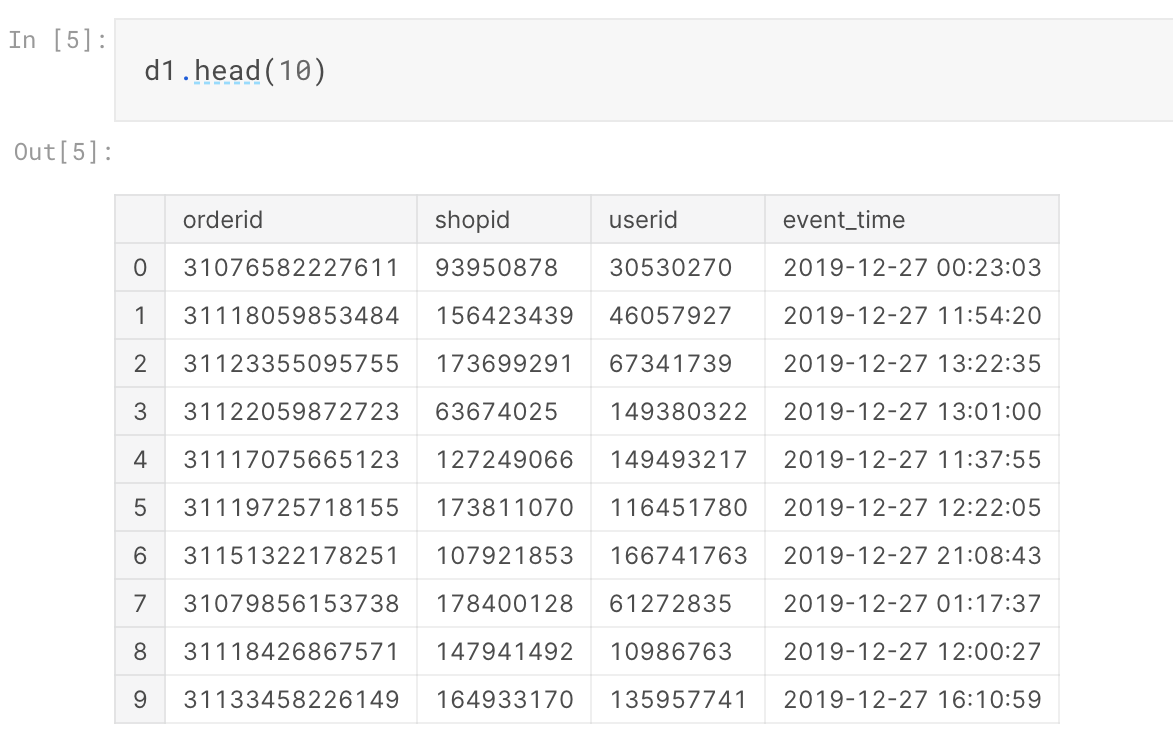 Dữ liệu 10 dòng đầu
Dữ liệu 10 dòng đầu
Để tính concentrate rate cho từng shopid trong mỗi interval 1 giờ, chúng ta query dữ liệu theo điều kiện shopid, event_time và end_time và previous_time (nếu chọn event_time là thời điểm bắt đầu interval thì end_time là thời điểm kết thúc interval, ngược lại chọn event_time là thời điểm kết thúc thì previous_time sẽ là thời điểm bắt đầu) với từng đơn hàng.
Sau khi xác định shop có brushing, ta giữ lại tất cả các orderid trong khoảng thời gian brushing time.
delta = pd.Timedelta(hours=1)
order_list = set() # store other rows that relevant to a brushing rows
shop_query = dict() # to store query for shopid to quickly access
i = 0
while i < row:
# if i % 10000 == 0:
# print(i)
r = d1.iloc[i]
end_time = r.event_time + delta
previous_time = r.event_time - delta
q = shop_query[r.shopid] if r.shopid in shop_query else d1[d1.shopid == r.shopid]
shop_query[r.shopid] = q
q_n = q[q.event_time.between(r.event_time, end_time)]
q_p = q[q.event_time.between(previous_time, r.event_time)]
con_rate_p = len(q_p)/q_p.userid.nunique()
con_rate_n = len(q_n)/q_n.userid.nunique()
if con_rate_p >= 3:
order_list.update(list(q_p.orderid.unique()))
if con_rate_n >= 3:
order_list.update(list(q_n.orderid.unique()))
i+=1
Khi một shop được xác định là brushing, cần phải xác định userid nào là brusher. Trong thời gian brushing time của một shopid, có thể có nhiều userid đặt hàng. Vì vậy chúng ta cần tìm user có user proportion cao nhất, nếu có nhiều user có cùng user proportion cao nhất thì phải trả về tất cả các user này.
def find_max(userid_list, user_p_list):
max_value = max(user_p_list)
maxs_index = []
for i, value in enumerate(user_p_list):
if value == max_value:
maxs_index.append(i)
max_user = [ userid_list[i] for i in maxs_index]
return max_value, set(max_user)
Tương tự, cùng một shopid có thể có nhiều brushing time khác nhau. Mỗi brushing time sẽ phải tìm ra userid có user proportion cao nhất. Ta sẽ chọn userid có user proportion cao nhất trong các userid đã tìm được từ các brushing time. Nếu có nhiều userid có cùng user proportion cao nhất thì chọn tất cả.
d2 = d1[d1.orderid.isin(order_list)]
shop_list = dict() # to store shopid with userids having highest user proportion
def add_to_list(shopid, max_tuples):
if shopid not in shop_list:
shop_list[shopid] = max_tuples
return
max_value, max_user = shop_list[shopid]
max_v, max_u = max_tuples
if max_v > max_value:
shop_list[shopid] = max_tuples
elif max_v == max_value:
shop_list[shopid] = (max_value, max_user.union(max_u))
# Process brushing order set
d2_uniq_shop = d2.shopid.unique()
for shopid in d2_uniq_shop:
q = d2[d2.shopid == shopid]
user_list = q.userid.unique()
sum_order = len(q)
user_proportion = []
for userid in user_list:
user_proportion.append(len(q[q.userid == userid])/sum_order)
max_value, max_user = find_max(user_list,user_proportion)
add_to_list(shopid, (max_value, max_user))
Sau khi có tất cả các shopid và userid cần tìm, chúng ta sẽ ghi file để làm submission.
# Get unique shopid
unique_shopid = d1.shopid.unique()
# Format userid for each shopid
userid_shopid = []
for shopid in unique_shopid:
userid = "0"
if shopid in shop_list:
max_value, max_user = shop_list[shopid]
userid = "&".join([str(u) for u in sorted(list(max_user))])
userid_shopid.append(userid)
Cuối cùng là ghi file và nộp.
sms = pd.DataFrame({
"shopid": unique_shopid,
"userid": userid_shopid
})
sms.to_csv("/kaggle/working/submission.csv", index=False)
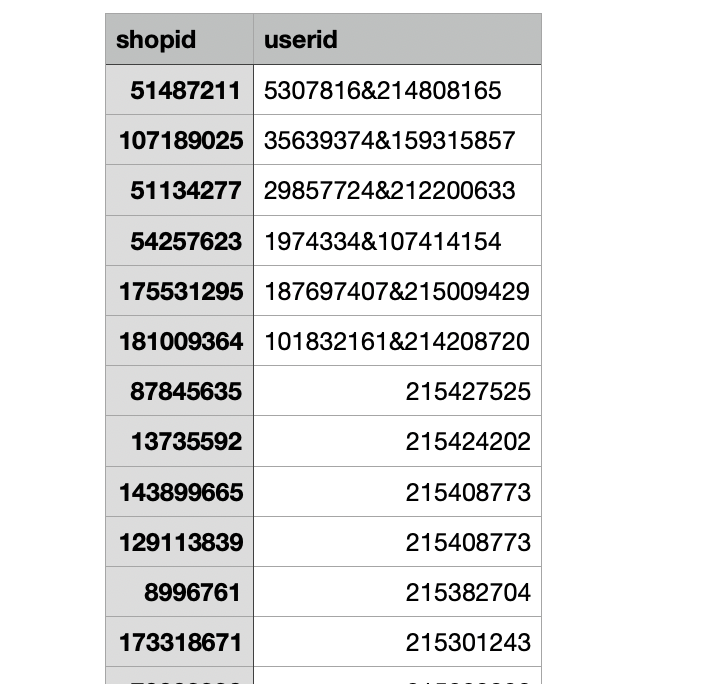 Kết quả dự đoán sắp xếp descending theo userid
Kết quả dự đoán sắp xếp descending theo userid
Các bạn có thể xem toàn bộ notebook, dữ liệu tại GitHub hoặc Notebook của nhóm trên Kaggle.
4. Nhận định
Trong quá trình giải quyết problem, team cũng đã tìm ra một vài điểm không hợp lý trong bộ rule được mô tả và cũng có người nhận ra điều đó:
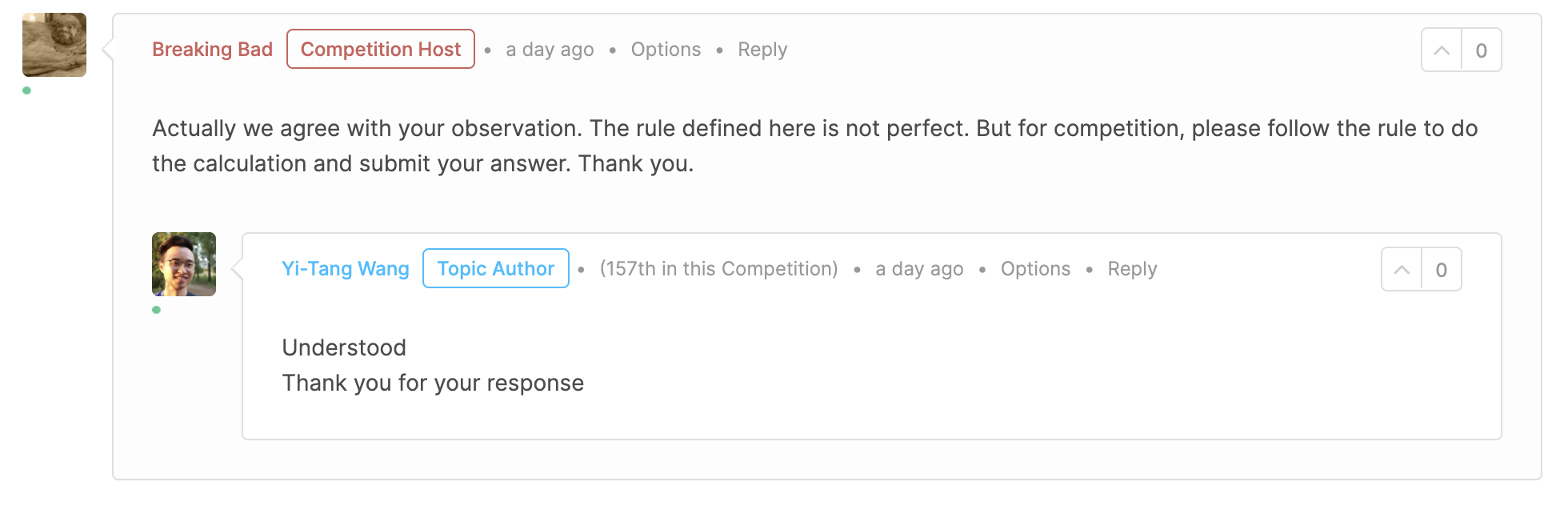 Đây là sân chơi của anh và mấy chú phải nghe anh :D
Đây là sân chơi của anh và mấy chú phải nghe anh :D
Câu trả lời của Shopee đơn giản là “đây là sân chơi của anh và mấy chú phải nghe anh” :D. Dễ hiểu, cuộc thi là cuộc thi, các rule đưa ra chỉ để phục vụ cuộc thi mà thôi. Nếu đưa ra một bộ rule hoàn chỉnh thì có thể bọn order brushing sẽ biết mà lách luật :D
Cảm ơn đồng đội đã cùng mình chiến hết sức.
Many thanks for my teammate @hoanghouit (Business Analyst), @XuanVuong (Business Analyst), @PhamVanMinh272 (Data Engineer).

Bình luận
Cảm ơn bạn
Your comment has been submitted and will be published once it has been approved. 😊
OK